
티스토리 뷰
1. 베이지안은 무엇인가요?
: 실제로 관측된 데이터를 사용하여 확률 분포를 고려합니다.
2. 빈도주의자는 무엇인가요?
: 선택의 가설을 조건으로 하며 관찰 여부에 관계없이(표본에 대한) 경험적으로 데이터의 분포를 고려합니다.
3. 가능도(우도)는 무엇인가요?
: 매개변수 값 세트가 제공된 일부 관측된 결과의 확률은 결과가 제공된 매개 변수 값 세트의 가능성으로 간주됩니다.
주어진 표본 x들을 통하여 모집단의 모수 파라미터에 대한 추정이 그럴듯한지를 나타냅니다.
가능도란 어떤값이 관측 되었을 때, 이것이 어떤 확률 분포에서 왔을 지에 대한 확률입니다.
(확률이란 주어진 확률 분포가 있을 때, 관측값 혹은 관측 구간이 분포 안에서 얼마의 확률로 존재하는가를 나타내는 값)
가설 로 세워진 확률 분포에 대해서 관측값을 넣어서 나온 결과값은 Likelihood 이고,
반대로 실제 고정된 확률 분포에 관측값을 넣었을 때 나온 결과값이 확률 입니다.
4. p-value(유의확률)는 무엇인가요?
: 귀무가설이 맞다는 전제하에, 통계값이 실제로 관측된 값 이상일 확률을 의미합니다.
"모분포의 평균이 100 이다"라는 귀무가설이 참이라는 가정 하에서, 100 개의 데이터를 sampling 할 때 이론적으로 나올 수 있는 평균의 분포에서, 지금 내가 갖고 있는 값인 95 보다 큰 값이 나올 수 있는 확률. 그것이 p-value 이다.
p-value는 귀무가설이 맞다는 전제 하에, 관측된 통계값 혹은 그 값보다 큰 값이 나올 확률이다.
p-값은 귀무가설이 옳다는 가정 하에서 실제 관측된 값 또는 그 이상 극단적인 검정통계량 값을 얻을 확률을 의미한다
p-value is a number between 0 and 1. Based on the value it will denote the strength of the results. The claim which is on trial is called Null Hypothesis.
Low p-value (≤ 0.05) indicates strength against the null hypothesis which means we can reject the null Hypothesis. High p-value (≥ 0.05) indicates strength for the null hypothesis which means we can accept the null Hypothesis p-value of 0.05 indicates the Hypothesis could go either way. To put it in another way,
High P values: your data are likely with a true null. Low P values: your data are unlikely with a true null.
5. p-value의 예시를 말해주세요.
:
실험 결과에 따르면 동전이 총 20 번을 던져서 14 번 앞면이 나오는 것으로 가정합니다.
귀무 가설 (H0) : fair coin
관찰 O : 20번을 던져서 14번이 앞면이 나옴.
H0 = Prob (≥ 14 heads 또는 ≥ 14 tails) = 0.115 인 경우 관측치의 p- 값 O
계산 된 p- 값이 0.05를 초과하므로 관측치가 귀무 가설과 일치합니다.
20 번의 플립 중 14 개 헤드의 관측 결과는 우연히 발생할 수 있습니다.
6. 샘플링은 무엇인가요?
: 표본 추출은 모집단에 대한 정보를 얻기 위해 속해있는 하위 집단을 선택하는 고르는 일입니다.
7. 샘플링의 방법은 무엇이 있나요?
:
- Simple Random (purely random),
- Systematic( every kth member of population),
- Cluster (population divided into groups or clusters)
- Stratified (divided by exclusive groups or strata, sample from each group) samplings.
8. mode(최빈값)은 무엇인가요?
: 주어진 데이터에서 가장 자주 발생하는 값을 말합니다.
9. 중앙값은 무엇인가요?
: 데이터의 중간에 있는 값으로, 상위에서 절반 혹은 하위에서 절반의 위치에 해당하는 값입니다.
이때 값의 위치는 크기 순으로 정렬되었다고 생각합니다.
10. skewness는 무엇인가요?
: 표본 평균 주위의 데이터의 비대칭성을 측정한 척도입니다.
양수이면 데이터가 더 오른쪽으로 음수이면 데이터가 왼쪽에 더 많이 퍼집니다.
11. 분산은 무엇인가요?
: 해당 데이터가 데이터들의 평균으로부터 얼마나 떨어져 있는지를 나타냅니다.
12. Kurtosis(첨도)는 무엇인가요?
: 첨도는 확률 분포가 얼마나 뾰족한지의 정도를 나타내는 척도입니다.
관측치들이 얼마나 집중적으로 중심에 몰려있는 가를 측정할 때 사용합니다.
13. 공분산은 무엇인가요?
: 두 변수가 얼마나 다른지를 나타내는 척도입니다.
2개의 확률 변수의 상관정도를 나타내는 값입니다.
공분산의 비슷한 목적으로 있는것이 상관 계수입니다.
공분산의 문제점으로는 두 확률 변수의 단위의 크기에 영향을 받는 다는 것입니다.
상관계수는 공분산을 분산의 크기로 나눠주어 절대적 크기에 영향을 줄여서 단위화 시킨것이라고 생각할 수 있습니다.
14. T-test(T검정)는 무엇인가요?
: 간단하게는 두 집단간의 평균을 비교하는 방법입니다.
두 집단간의 비교에만 사용되며 그 이상의 분산분석에는 ANOVA를 사용합니다.
15. 대립 가설은 무엇인가요?
: H1으로 주로 표기되며, 귀무가설(null hypothesis, H0)가 거짓이라면 항상 참이 되는 가설입니다.
16. 이항 분포의 식은 어떻게 되나요?
: 연속된 n번의 독립적 시행에서 각 시행이 확률 p를 가질때의 이산 확률 분포입니다.
베르누이 시행이라고도 불립니다.
17. 중심 극한 정리는 무엇인가요?
: 표본 크기가 증감함에 따라 표본 평균의 표본 추출 분포는 정규 분포에 근접해 집니다.
먼저, sampling distribution을 먼저 설명합니다.
sampling distribution은 특정 모집단에서 추출한 많은 수의 표본을 통해 얻은 통계량의 확률 분포입니다.
중심 극한 정리는 샘플들의 평균의 샘플링 분포는 샘플의 크기가 커질수록 정규분포에 가까워집니다.

18. 귀무 가설은 무엇인가요?
: 귀무 가설(null hypothesis, H0)는 우리가 타파하고자 하는 주장을 말합니다.
우리가 증명하고자 하는 가설의 반대되는 가설, 효과와 차이가 없는 가설을 의미하며, 우리가 버리고자 하는 가설입니다.
예를 들어"A 유전자는 암을 유발한다"는 가설을 입증하기 위해 "A 유전자는 암을 유발하지 않는다"라는 귀무 가설을 설정합니다.
19. type1 과 type2 에러는 무엇이 다른가요?
: typ1에러는 귀무가설에 참이지만 귀무가설을 기각하는 오류입니다. 실제 음성인것을 양성으로 판정하는 경우입니다.
type2에러는 귀무가설이 거짓이지만 귀무가설을 채택하는 오류입니다. 실제 양성을 음성으로 판정하는 경우입니다.
20. 선형 회귀 분석에 필요한 가정은 무엇인가요?
: 다음과 같은 세가지 주요 가정이 있습니다.
- 선형성: 종속 변수와 독립변수 사이에는 선형관계가 있습니다. 이것은 종속 변수와 독립변수사이에 비선형 관계가 있고 선형회귀 모델이 적합하지 않고 예측이 실제와는 거리가 멀다는 결정적인 가정 중 하나입니다.
- 정규성 : Residual error는 정규분포로 가정합니다.
- 동질성 : 잔차(오류)는 X의 일정한 분산을 갖습니다.
21. selection bias는 무엇인가요?
: 편향성의 한 종류로서 데이터가 다양하게 선택, 샘플되지 못하고 특정집단에서 집중적으로 선택될 때 발생하는 편향성입니다.
이외에도 편향성에는 Size bias, undercoverage bias, response bias, Quota sampling bias등이 존재합니다.
22. 확률 분포, 확률을 요약 표현하는 척도에 대해서 설명하시오.
: 분포를 요약할 수 있는 척도는 크게 3가지 종류가 있습니다.

23. point 추정과 신뢰구간은 무슨 차이가 있나요?
: 점추정은 모집단의 파라미터를 예측하는 특정한 값을 구합니다. 모멘트, MLE와 같은 방법이 점추정입니다.

신뢰구간은 모집단의 파라미터를 포함할 수 있는 값의 범위를 제공합니다. 신뢰구간은 일반적으로 이 구간이 모집단의 파라미터를 포함할 가능성을 알려줍니다.
24. 신뢰구간은 어떻게 계산하나요?
: 모분산을 아는 경우에는 Z통계량을 사용합니다.
모분산을 모를때는 T분포를 사용하여 신뢰구간을 추정합니다.


25. T분포와 카이제곱 분포
: T분포는 표본평균을 이용해 정규분포의 평균을 해석할 때 많이 사용합니다.
t분포는 모집단이 정규분포를 하더라도 분산 σ²이 알려져 있지 않고 표분의 수가 적은 경우에, 평균 μ에 대한 신뢰구간 추정 및 가설검정에 아주 유용하게 쓰이는 분포이다.
- 확률변수 X가 표준정규분포 N(0,1)을 따르고, 확률변수 Y가 자유도 n인 카이제곱 분포를 따르면서, X와 Y가 서로 확률적으로 독립일 때,
- T = X / (√(Y/n)) 로 정의되는 확률변수는 자유도 n인 t분포, 즉 t(n)을 따른다.
여기서 중요한 것은 이렇게 t분포는 정규분포 모집단을 가정하고 있다는 것이다. 그러므로, 모집단이 정규분포가 아닌 경우에는 표본 분석시 t분포를 활용해서 구한 신뢰구간이나 p-value는 정확하지 않을 가능성이 높다.
26.ANOVA와 그 응용에 대해서 설명해주세요. (내가 쓰고도 무슨 소린지 모르겠네...)
:ANOVA는 analysis of variance의 약자입니다. 여러샘플의 평균을 비교하는데 사용되는 방법입니다.
2개의 표본에 대해서 평균간에 유의미한 차이가 있는지의 여부는 Z분포 혹은 T검정을 사용하여 평가할수 있지만, 2개 이상의 표본의 경우에는 적용하기 어렵습니다.(샘플이 증가하면서 번거로워질수 있음. 예를들어 4개의 표본에 대해서 12번의 T검정을 해야함.)
그러한 경우에는 ANOVA를 사용하여 비교 할 수 있습니다.

27. Factor analysis와 pricipal component analysis의 차이는 무엇인가요?
: 두 방법 모두 데이터이 차원을 줄일수 있는 방법입니다.
그러나 일반적으로 요인 분석을 사용하여 측정된 변수의 관계의 패턴을 단순화 합니다.
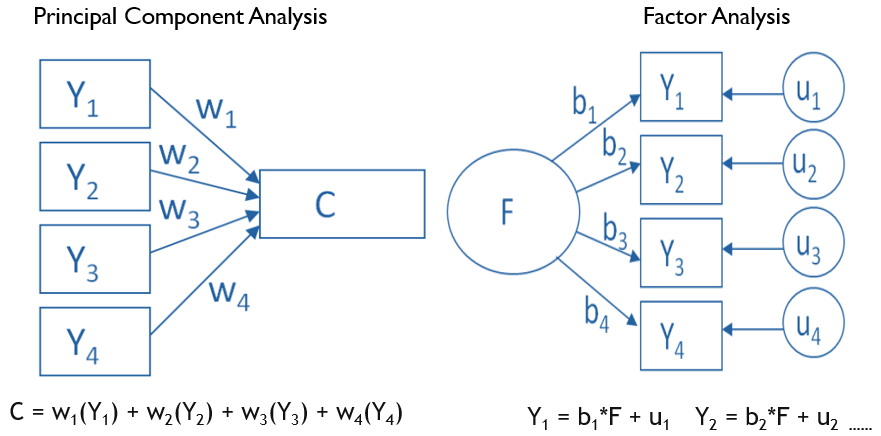
요인 분석은 매니페스트 변수는 요인과 고유 요인 또는 특징의 선형 조합니다.
PCA는 몇개의 변수를 사용하여 많은 변수의 공통적인 특징, variation을 요약합니다.
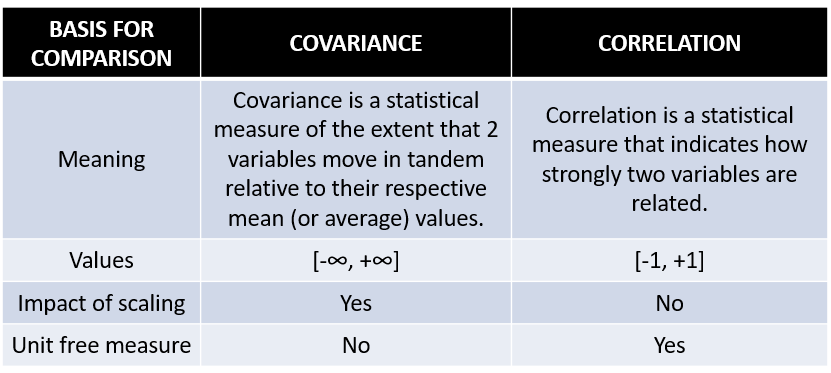
28. 공분산과 상관계수의 차이점은 무엇인가요?
:상관계수와 공분산은 모두 두개의 랜덤 변수에 대해서 종속성을 비교하는 방법입니다.
상관계수는 변수가 표준화 될 때 관찰 할 수 있는 공분산의 특별한 경우입니다.

'개발 일반' 카테고리의 다른 글
| [python] csv를 json 포맷으로 바꾸기 (0) | 2020.01.06 |
|---|---|
| [python] urllib.error.URLError: <urlopen error [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:1076)> 에러 해결 (0) | 2019.12.06 |
| Hadoop 기술 면접 대비 (1) | 2019.10.08 |
| Spark 기술 면접 대비 (0) | 2019.10.07 |
| Java 기술 면접 대비 (0) | 2019.10.03 |